AWS 전문가와 함께 익히는 모델 서빙 패턴
개요
머신 러닝 알고리즘은 지난 10여년 간 급속도로 발전했으며, 수많은 사전 훈련된(pre-trained) 모델을 그대로 활용하거나 파인 튜닝으로 특정 유즈케이스에 적합한 모델로 개선함으로써 다양한 어플리케이션을 빠르게 개발할 수 있습니다. 모델 배포는 MLOps의 핵심 구성 요소이며 MLOps가 비즈니스와 함께 확장됨에 따라 인프라 구축의 중요성이 대두되고 있습니다. 하지만, 온프레미스에서 머신 러닝 모델을 프로덕션에 배포하고 관리하려면 인프라 구축 및 관리에 많은 노력과 비용이 들어가며 머신 러닝, 인프라 관리, 소프트웨어 엔지니어링에 모두 능숙한 실무자가 필요합니다. Amazon SageMaker(이하 SageMaker)는 대용량 모델 훈련과 모델 서빙에 필요한 인프라 관리에 대한 부담을 덜고 핵심 로직에 집중할 수 있게 도와 주는 AWS의 핵심 서비스입니다. 컴퓨팅 인프라의 비용을 최적화하고 서비스 인프라를 탄력적으로 확장할 수 있으며, 마이크로서비스 배포에 특화되어 있기에 빠른 실험 및 배포에 적합합니다.
본 워크샵은 SageMaker의 대표적인 모델 서빙 패턴들을 익힐 수 있게 구성되어 있으며, 각 모듈은 독립적으로 수행할 수 있습니다. 학습이 목적인 분들은 스텝 바이 스텝으로 모든 모듈을 실행하셔도 되지만, 특정 모델 서빙 패턴에 대한 예시만 필요한 분들은 해당 모듈만 실행하시면 됩니다.
Requirements
실습 환경 및 주의 사항
- AWS Region:
us-east-1orap-northeast-2 - Browser: 반드시 최신 버전의 Chrome, Firefox를 사용하세요. Internet Explorer는 제대로 동작하지 않을 수 있습니다.
- 주의 사항: 노트북(Notebook) 안의 코드 셀(Code cell) 실행 후 결괏값이 나오는 데는 수 초가 걸립니다.
대상자
- 학계나 연구소의 머신 러닝 과학자가 아닌 기업의 머신 러닝 엔지니어
- SageMaker 기초 개념: 본 워크샵은 SageMaker에 대한 기초 개념을 이해했다고 가정합니다. 만약 SageMaker를 처음 접해 보시거나 핵심 개념을 파악하지 못하셨다면, 아래 링크 자료들을 숙지해 주세요.
시나리오
기본적인 머신 러닝 역량을 갖추고 토이 프로젝트로 모델 서빙 경험도 있는 머신 러닝 엔지니어 A군은 디지털 트랜스포메이션을 적극 추진하고 있는 기업 B에 입사하여, PO(Product Owner)에게 특명을 받았습니다.
- 인프라 구축 및 비즈니스 추진을 거쳐 DS(Data Science)팀의 인력들이 현업에 적용하기 위한 머신 러닝 모델들을 훈련했어요. 모델들은 한국어 자연어 처리 모델과 이미지 분류/물체 검출 모델 등의 100여가지 파인 튜닝 모델이 섞여 있습니다. 하지만, 막상 프로덕션에 적용하려니 다들 모델 서빙을 꺼려하고 있어요. 그렇다고 밑바닥부터 모델 서빙 인프라를 다시 구축하거나 MLOps 인력을 새로 뽑자니 너무 많은 시간이 소요됩니다. 사업계획이 마감되기 전에 C-레벨에게 보고를 올려서 내년 예산 투자를 받기 위해서는 1달 내로 모델 서빙이 완료되어야 해요. 다행히 AWS 담당자분께서 SageMaker란 서비스를 활용하면 모델 서빙을 관리형으로 구축할 수 있다고 하는데, A님이 직접 오너십을 가지고 이끌어 보시겠어요? 먼저, 프로젝트 이해관계자들과 미팅을 주선해 보세요.
A군은 특명을 받고 걱정 반, 설렘 반의 마음으로 회의를 주선하였습니다. 역시나 회의에 참석한 담당자들은 각자의 의견을 늘어놓기 시작합니다.
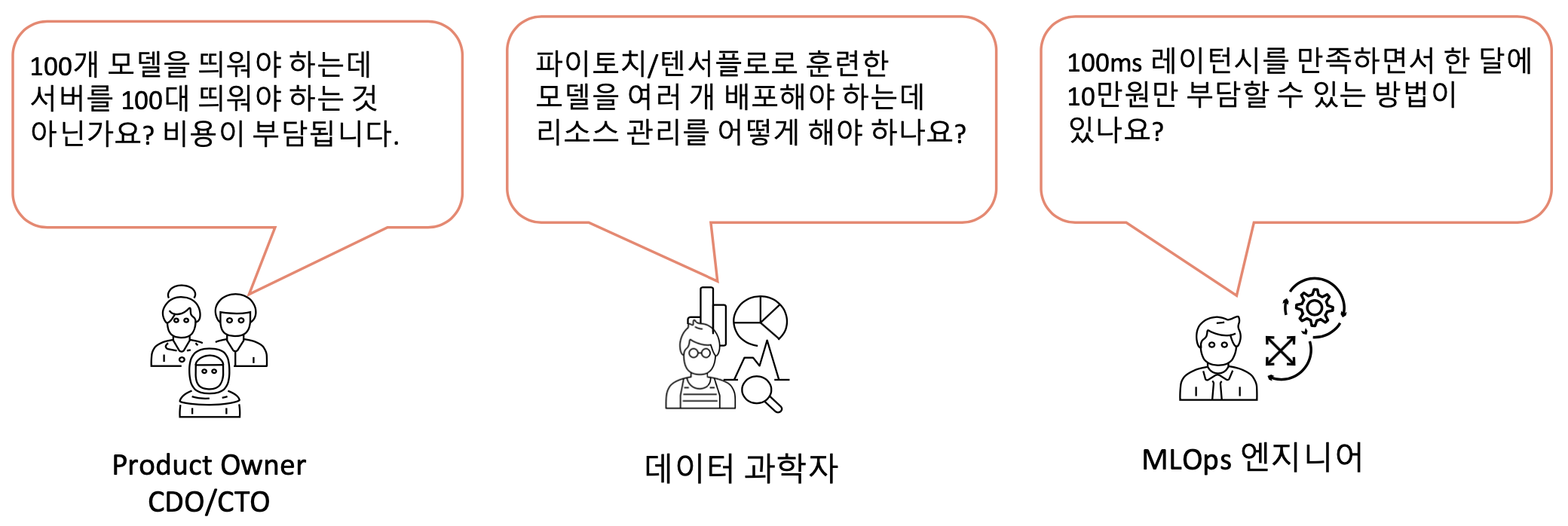
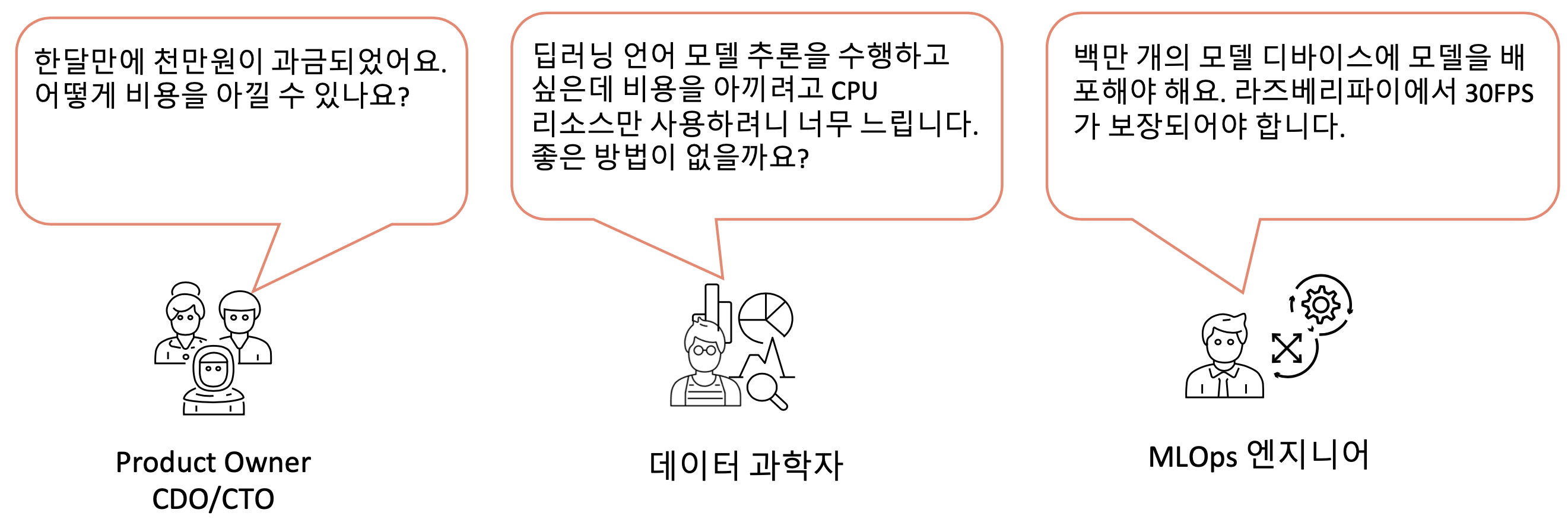
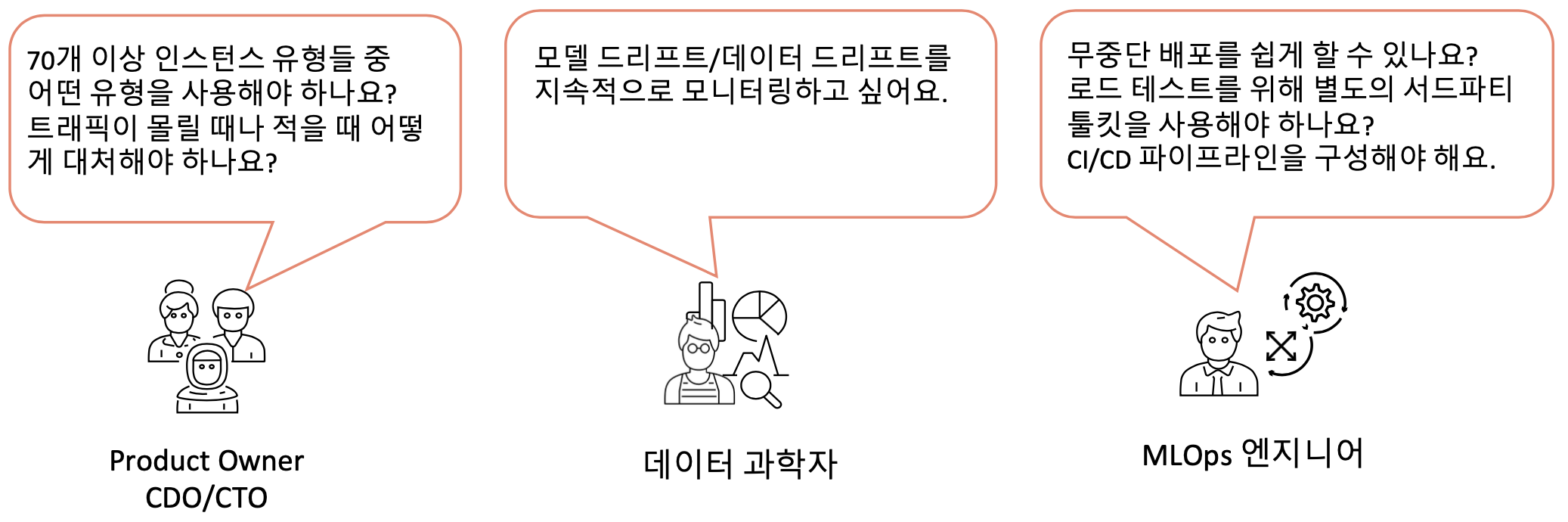
아니! 비용을 아끼면서 모델을 수백 개 띄우고 100ms 미만 레이턴시를 만족하라니, 토끼 한 마리 잡기도 여려운데 여러 마리를 잡으라고 하네요. 이게 어찌된 영문인지 머리가 아파옵니다.
“게다가 내가 DevOps 전문 인력도 아니고 이걸 어떻게 하라고?” 라고 속으로 불평하면서도 “그래, AWS 학습 리소스가 있잖아. 검색하면서 셀프 스터디하거나 AWS의 도움을 받으면 되겠지.“라고 긍정 에너지를 뿜뿜하는 멋진 A군!
하지만, A군은 몇 시간 후 방대한 AWS 학습 리소스에 넋이 나가버립니다. “에휴~ 학습 리소스가 많으면 뭘해? 한국어 예제도 없고 참고자료들은 중구난방이고…”
그렇다면 AWS AIML 전문가들의 도움을 받으면 되지 않을까? 라고 생각해서 AWS에 컨택한 A군! 그러나 AWS AIML 전문가들이 이미 일정이 꽉 차 있기에 당장 도움을 드릴 수 없다고 합니다. 대신 AWS는 그들의 경험을 A군이 쉽게 따를 수 있게 정리한 모델 서빙 워크샵을 A군에게 안내했습니다.
모델 서빙 워크샵의 목차를 본 순간, A군의 근심 가득한 얼굴이 활짝 펴집니다. “그래! 이거야!!”
Contact
- Contributor: 김대근 (AWS Sr AIML Specialist Solutions Architect)
- 해당 워크샵과 관련한 문의 사항이나 AIML 도입에 관심이 있는 분들은 아래 메일로 문의 바랍니다.